Transkribieren mit Whisper
 “A man whispering through a pipe sitting in an arm chair”, Stable Diffusion Online & Axel Dürkop, 05.02.2023
“A man whispering through a pipe sitting in an arm chair”, Stable Diffusion Online & Axel Dürkop, 05.02.2023
Schon immer fand ich die Vorstellung sehr attraktiv, dass meine wörtliche Rede möglichst in Echtzeit verschriftlicht wird. Ich tippe zwar recht schnell mit zehn Fingern, aber nicht so schnell, wie ich denke oder spreche. Bisherige Lösungen haben mich nicht überzeugt, weil sie entweder proprietär oder zu ungenau waren oder mit der eigenen Stimme angelernt werden mussten.
Whisper von OpenAI
Die KI-Modelle rund um Whisper von OpenAI (auch bei GitHub) lassen meinen Traum wieder aufleben und geben Anstoß für weitere interessante Szenarien. In den folgenden Abschnitten dokumentiere ich, was mir mithilfe von wenigen Schritten auf dem eigenen Rechner gelungen ist. Dabei habe ich folgende Schritte durchlaufen:
- Installation von
whisper.cppund zugehöriger Sprachmodelle auf dem eigenen Rechner (Manjaro Linux auf Lenonvo X230 mit Core i7 vPro, also nicht sehr leistungsstark). - Einsprechen eines Textes mit Audacity bei absichtlich minderer Qualität.
- Transkription mit Whisper.
- Übersetzung der Transkription mit Whisper.
Installation von Whisper
Eines der vielversprechendsten Features von Whisper ist, dass es ohne Kontakt zum Internet, also offline, die Transkription von Sprache durchführt, nachdem es einmal installiert wurde. Dafür sind für die Dateien der Modelle einige Gigabyte herunterzuladen, aber das ist ja wohl auf den meisten Rechnern kein Problem mehr.
Whisper kann in einer Python-Umgebung installiert werden, was weiterführende Anwendungsszenarien ermöglicht, z. B. im Zusammenspiel mit anderen OpenAI-Produkten wie DALL-E 2 und GPT-3/chatGPT, die über komfortable APIs verfügen.
Georgie Gerganov stellt auf GitHub eine Portierung in C/C++ zur Verfügung, die sehr schnelle Ergebnisse auch ohne Unterstützung einer Grafikkarte liefert. Folgt man nach dem Klonen des Repos der Anleitung, lässt sich whisper.cpp unter allen Betriebssystemen ausführen. Da in den Repos von Manjaro auch ein fertiges Paket zur Installation angeboten wurde, habe ich diesen Weg gewählt.
$ yay -S whisper.cpp-git
$ yay -S whisper.cpp-model-base.en
Die erste Zeile installiert das Programm, das zweite das auf Englisch spezialisierte Modell. Mit
$ yay -S whisper.cpp-model-base
habe ich dann noch ein allgemeines Modell installiert, das auch sehr passabel deutschsprachige Tondateien transkribiert hat. Mit
$ yay -S whisper.cpp-model-medium
habe ich anschließend noch ein komplexeres Modell installiert, um die Unterschiede in der Qualität zu testen.
Transkribieren und einsprechen eines Textes
Der Ordner samples in dem Repo von Georgi Gerganov enthält eine Tondatei mit den notwendigen Eigenschaften für die Transkription. Der folgende Befehl führt somit auch zu einem ersten Ergebnis und dient gleichzeitig als Test, dass Whisper korrekt läuft:
$ whisper.cpp-base.en -f samples/jfk.wav
führt im besten Fall zu folgendem Ergebnis:
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
Nun, würde das auch so gut funktionieren, wenn ich einfach ein Tonsample von mir transkribiere?
Nach ein wenig Herumexperimentieren mit den richtigen Einstellungen in Audacity hatte ich Erfolg. Aufnahmen müssen für whisper.cpp mit 16.000 Hz im WAV-Format bereitgestellt werden, weshalb ich die Einstellungen für meinen Test so vorgenommen habe (Neustart von Audacity nötig).
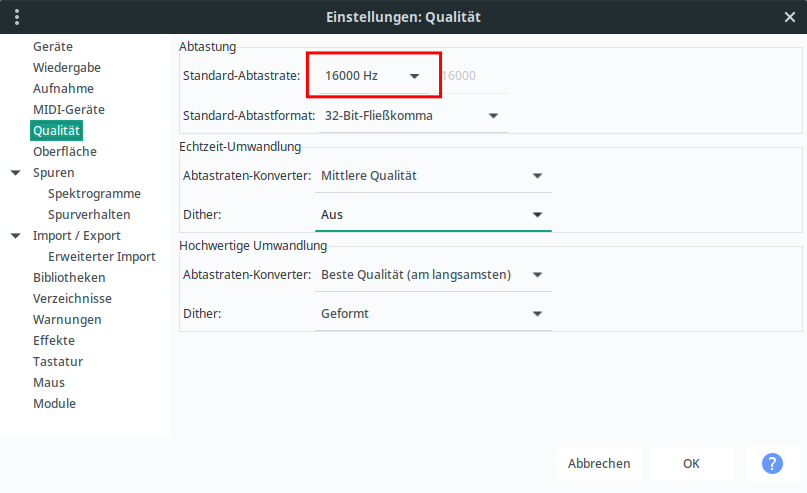
Mit dem eingebauten Mikro meines X230 habe ich nun ohne viel Mühe und bei gewollt mittelmäßiger Qualität ein Gedicht eingesprochen.
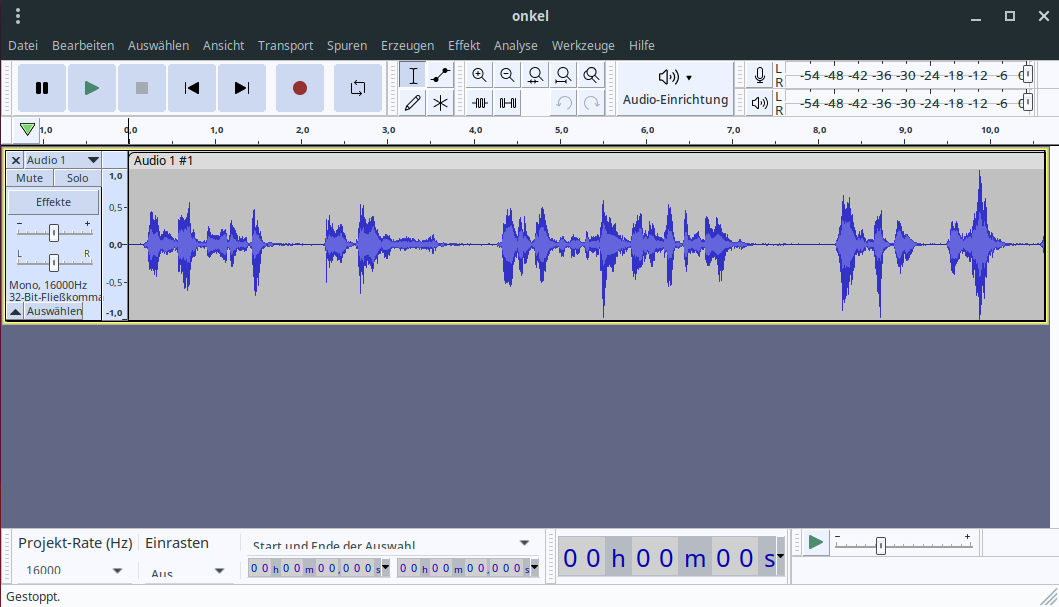
Die Tondatei stelle ich auch gern zur Verfügung.
Transkription mit Whisper
Der folgende Befehl transkribiert nun diese Datei und schreibt das Ergebnis in verschiedenen Dateiformaten weg:
$ whisper.cpp-medium -l de -nt -otxt -ovtt -osrt -f samples/onkel.wav -of ./onkel
-l de steht dabei für die Sprache der Tondatei, hier Deutsch. -nt gibt an, dass keine Timestamps in der Textdatei ausgegeben werden sollen. -otxt gibt an, dass die Transkription in eine txt-Datei erfolgen soll. vtt und srt werden mit -ovrt und -osrt angegeben. -of gibt an, unter welchem Pfad bzw. Namen die Transkription gespeichert werden soll. In diesem Fall werden die drei Dateien onkel.txt, onkel.vtt und onkel.srt geschrieben. Der Vorgang hat knapp zwei Minuten gedauert.
Um die Qualität der Transkription mit dem medium-Modell hier zu zeigen, im Folgenden der Inhalt der txt-Datei. Die Umbrüche habe ich manuell ergänzt, sonst ist nichts korrigiert oder geändert.
Wer im Dorfe oder Stadt
einen Onkel wohnen hat,
der sei höflich und bescheiden,
denn das mag der Onkel leiden.
Morgens sagt man "Guten Morgen,
haben Sie was zu besorgen?"
Bringt ihm, was er haben muss,
Zeitung, Pfeife, Fidibus?
Oder sollt es wo im Rücken,
drücken, beißen oder zwicken,
gleich ist man mit Freudigkeit,
Dienst beflissen und bereit.
Oder sei es nach einer Prise,
dass der Onkel heftig niese,
ruft man "Prosit", also gleich
"Danke, wohl bekomme es Euch".
Oder kommt er spät nach Haus,
zieht man ihm die Stiefel aus,
holt Pantoffel, Schlafrock, Mütze,
dass er nicht im Kalken sitze.
Kurz, man ist darauf bedacht,
was dem Onkel Freude macht.
Zum Vergleich hier der Originaltext dieses Fünften Streichs aus Max und Moritz von Wilhelm Busch.
Übersetzung
Wenngleich nur für einige Szenarien der wissenschaftlichen Transkription sinnvoll und wohl eher brauchbar für die Untertitelung von Audio und Video in fremden Sprachen, zeige ich noch das Ergebnis der automatischen Übersetzung der Transkription ins Englische. Hierfür ist der Parameter -tr für translate notwendig. Andere Implementierungen von Whisper erlauben Übersetzungen auch in viele andere Sprachen.
$ whisper.cpp-medium -l de -nt -otxt -ovtt -osrt -f samples/onkel.wav -of ./onkel -tr
Das Ergebnis, ungeschönt, Umbrüche manuell ergänzt für eine bessere Darstellung:
If you have an uncle
in the village or city,
be polite and modest,
because the uncle likes to suffer.
In the morning you say, "Good morning,
do you have something to get?"
Bring him what he needs,
newspaper, pipe, fidibus?
Or should it be somewhere in the back,
press, bite or twist,
you are happy, service-bound and ready.
Or, after a prize
that the uncle sneezes heavily,
you call "Prosit", so right away.
Thanks, I'll get it for you.
Or he comes home late,
you take off his boots,
get slippers, sleeping bag, hat,
so that he doesn't sit in the cold.
In short, you are focused on
what makes the uncle happy.
Nun ja, hier ist nach wie vor der Mensch für die Qualitätskontrolle gefragt.
Fazit
Die Qualität von Whisper ist beeindruckend. Dass ein vorhergehendes Anlernen der Software für die eigene Stimme oder gar verschiedene Interviewpartner*innen nicht mehr notwendig sind, lässt zahlreiche neue Anwendungsszenarien zu. Vor allem in der qualitativen Sozialforschung kann Whisper ein mächtiges datenschutzkonformes Werkzeug sein, weil auch vertrauliche Daten den eigenen Rechner für die Transkription nicht mehr verlassen müssen. Mitchell Clark diskutiert diesen Vorteil in seinem Erfahrungsbericht zu Whisper, stellt aber auch die Kehrseite dieser Medaille heraus. Einer, der sicher den Run auf Whisper bremsen wird, ist die (bisherige) Unmöglichkeit, Sprecher*innenrollen zu kennzeichnen.
Dass die Nutzung von Whisper hier noch mühselig erscheint, soll niemanden schrecken. Ich mag ja die Kommandozeile sehr und bin froh, dass die KI-Modelle auf diese Weise nutzbar sind. Wer lieber mit grafischen Oberflächen arbeitet, muss sich sicher nur noch wenige Tage gedulden, dann sind weitere Anwendungen im Netz, die den Prozess vereinfachen.
Angesichts der Berichte über die menschenunwürdigen Arbeitsbedingungen im Qualitätssicherungs- und Trainingsprozess von OpenAI, von dem TIME am 18.01.2023 berichtete, wird meine Freude über die aktuelle Entwicklung von KI-Sprachmodellen stark geschmählert. Inwieweit auch das Training von Whisper unter solchen Umständen stattfand, vermag ich nicht zu sagen. Blickt man auf die Investitionssummen rund um chatGPT, die u.a. Microsoft in Aussicht gestellt hat, ist m.E. die Forderung berechtigt, dass alle an der Produktion von KI-Anwendungen Beteiligten anständig behandelt und bezahlt werden könnten.